How NLP Can Get You an 800 CR on the SAT
Natural language processing (NLP) is a subfield of artificial intelligence that addresses the problem of getting computers to meaningfully process written languages. The SAT is a standardized test used primarily for college admissions, and it consists of math, writing, and critical reading (CR) questions.
CR is meant to assess students’ comprehension skills, which, to the College Board, means seeing if they know a million esoteric vocabulary words. I analyzed a few official SAT practice tests and found that around $30\%$ of the CR section is direct vocabulary assessment. But that’s not the only reason learning new words is essential to doing well. A strong vocabulary will help you articulate your thoughts on the essay and breeze through the passages featured on the test.
What the hell does NLP have to do with anything?
I’m a programmer, so in the months prior to my SAT date, I wrote a bunch of programs to help me study vocabulary, my Achille’s heel. I made websites, Android apps, and desktop programs to optimize my studying as much as possible. Yet as hard as I had tried to find a secret, hyper-efficient method, my creations only ever made it mildly easier to study. The problem with vocabulary is that there’s nothing conceptual about it. It’s all about memory, so there aren’t any elegant shortcuts to speed up learning.
I’ll bet you’ve heard your teachers tell you, “Reading is the best way to learn new words!” Admittedly, the logic is sound. Vocabulary is about memory, and it’s easy to remember a word if you’re constantly exposed to it. Therefore, reading challenging books expands your vocabulary because doing so inundates you with words you don’t know… right? I’m sure you don’t need me to tell you that this is a very unsatisfying answer.
It’s not that I disagree, but rather that this “indirect” style of learning fails to provide an immediate sense of progress. Not to mention you, like me, don’t have time in your schedule to read a couple of additional books a week. Don’t worry though, there’s hope. According to this article:
… if you go online and visit web pages in one day - which is a simple task when you could email, blogs, youtube etc - you’ll see on average words; War & Peace was only 460,000 words
$200$ pages means you’ll “see” approximately $500,000$ words a day. You won’t necessarily read and think about them. Let’s estimate a clean $10\%$ read rate (depends on reading speed and engagement). I’ll even give you Sundays off. This means on average, you’ll read $50,000$ words a day and $300,000$ words a week through your internet browser (including mobile browsers). This is equivalent to the number of words in the entire Hunger Games trilogy. So, no. You really don’t have time to read a couple extra books a week. You have time to read three.
Of course, it’s not so simple. Sure, you’re reading hundreds of thousands of words, but I doubt the random web pages on the world wide web push you to your lexical limits. To really take advantage of this phenomenon, we need to figure out a way to increase the quality of words we’re reading. It’d be impossible and silly to contact every single publisher of words on the internet, so our solution must work within our own computers. Manipulating words on websites? Making them “smarter”? This is right up natural language processing’s alley! Let’s make a Chrome extension.
The Algorithm
Here’s the high level strategy: look at every single word on a webpage and replace simple ones with more complex words that mean, more or less, the same thing. This should expose us to the types of vocabulary words we long to know without negatively impacting our internet experience. This strategy sounds fine to me, but there are a couple problems. How will we know if a word is simple? What does that even mean in this context? How will we know if a “complex” replacement really is more complex? How the heck are we going to find words that mean the same thing?
Heuristic for Word Difficulty
If we assume that people use simple words more than they use advanced words, then this isn’t too difficult a quantity to estimate. We just need to look at which words get used the most to find simple words and the least for complicated words. Argh… but now we have another question to answer. How can we possibly know how many times a word has been used?
In natural language processing, corpora (plural of corpus) are used whenever you need to do… anything. A text corpus is a huge collection of words, sentences, or passages, often annotated with linguistic information and organized by source (e.g. oral, written, fiction). All we need to do is download a diverse, few-million word corpus and count the number of occurences of each word. If our corpus draws from a variety of language sources, we should get a good approximation of English word frequencies.
Finding Words with Equivalent Meanings
This is what synonyms were made for! All we need is access to a thesaurus and we’ll be set.
…except we have high standards and blind thesaurus bashing is unlikely to be very effective. Consider the following scenario. We have the sentence:
Leaves fall down in fall.
and a desire to spice up the repeated word, “fall”. If we blindly consult a thesaurus, we might end up with something like:
Leaves descend down in descend.
Remember: computers aren’t smart enough to realize it doesn’t make sense to use this word in both scenarios! We haven’t been nearly explicit enough. Errors abound in our current system because it has no conception of part of speech (POS). Quality thesauruses will separate synonyms by POS, so as long as the computer knows the POS of each word, our system should work.
Leaves descend down in autumn.
Unfortunately computing POS is a pretty difficult problem. Even humans have trouble tagging really confusing sentences! It’s not as if we can keep a list of the parts of speech of every word and just look it up when we need it. POS depends on context. To solve this problem, we really will need NLP. The technical details of how various POS tagging algorithms work are beyond the scope of this article, but here’s a quick run down of a common method:
First, we need a sufficiently large corpus. Our corpus needs to have thousands of sentences, and it must include the correct parts of speech of every single word.
Then we need to pore through this corpus and keep track of a few things. How often is each word each POS? For instance, perhaps “fall” is a verb 70% of the time and a noun the rest. Next, how often does each POS follow each other POS? If we know that nouns are very likely to follow adjectives, then we can make some pretty good predictions.
That rule came from the top of my head because I’m a native English speaker. Computers can come up with hundreds of such rules because they have the benefit of speed (and an inability to feel boredom). If we wanted to be fancy, we might even ask, “If I saw an 1) adverb and then I saw a 2) verb, how likely am I to see a 3) noun next?” for all possible POS combinations.
The next bit is the hard part. If we guess the POS of each word randomly, we can assess the quality of our guess with all the probabilities we calculated from our corpus. We just need to go through each word and consider: is this word likely to be this POS? Is this POS likely to follow the previous POS? How likely is this POS to follow the previous two POS? The specifics might sound confusing, but they’re unimportant.
Its’ pretty clear guessing randomly isn’t going to cut it. We do want the best possible POS assignments, after all. Seriously, what are the odds of guessing the correct POS for a $20$ word sentence? This is left as an exercise for the reader. There are just way too many possible POS combinations. Too many to check blindly, even if we use a really fast computer. Thankfully, this clever dude invented the Viterbi algorithm, which solves our exact problem.
Some Helpful Shortcuts
We know how to find appropriate words with equivalent meanings and we know how to assess word complexity. We have all the tools we need to finish the extension, but let’s take a step back and reconsider our intent.
We’re making this extension specifically to help us with SAT vocabulary. There are SAT word lists. Why learn random “big” words when we can learn specifically the ones we need? The word list I used when I first made this extension included both SAT and GRE words, but it’s no longer available online. That’s not a problem though because there are tons of free lists.
Here’s a new strategy that takes advantage of our insight. For every word on a webpage, if it’s a SYNONYM of an SAT word AND the same POS, replace it with that SAT word. We’re ignoring the whole bit about word difficulty because that was never the priority. Complexity was a proxy to our real goal - success with SAT words, something we now have direct access to.
Practical Considerations
As much as we’d like for this extension to produce perfectly fluid webpages, it doesn’t. It’s analogous to using a thesaurus to trick others into thinking you have a massive vocabulary. Not only must a word’s meaning make sense, but also its context. The algorithm I proposed doesn’t address this very important language feature, so there’s no way its results can be perfect.
That isn’t to say it isn’t useful. All we need to do is make it so our SAT word replacements appear in a little hovering box.
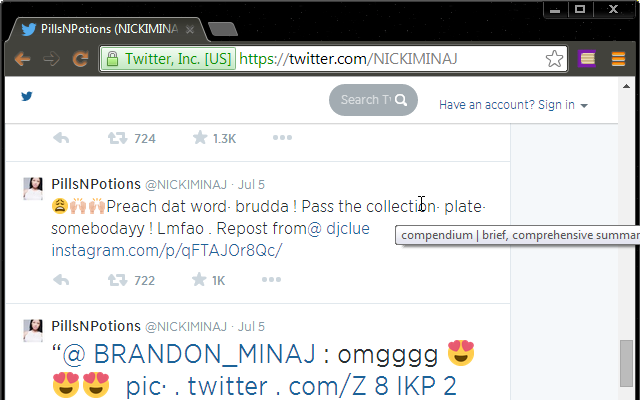
This way, we retain the fluidity of the original webpage while easily exposing ourselves to SAT words in relevant, memorable contexts.
You can check out my Smart Words browser extension on the Chrome webstore or, if you’re already keen to try it, . This was an immense help last year when I was studying for the SAT, and I’m sure that’ll be the case for you too, if you’re committed and stick with it.
Thanks to These Resources
This extension would have taken way longer to make if not for a few fantastic projects.
- jspos for providing the POS tagger
- the Big Huge Thesaurus for their wonderfully free API
- the excellent GRE/SAT wordlist I found that’s unfortunately no longer available. I still have all the data saved to my computer though! If you’d like it, email me or leave a comment.